


OS-shell挑战性任务实验报告
前言
本次实验中要求对MOS
LAB6中的shell进行增强,但是考虑到课程内实现的shell无内建指令,我在本次挑战性任务中直接重构了课程内部的shell实现,首先采用词法分析和递归下降语法分析进行指令的解析,得到一棵抽象的语法树(此处为二叉树),然后递归地执行该命令。
任务内容及实现方法
相对路径
当前路径维护
我在挑战性任务采用了在进程控制块中维护该进程的当前绝对路径以支持相对路径。
1234struct Env { // ...... char path[MAX_PATH];};
在创建进程(即调用env_create函数)时将被创建的进程的当前目录设置为根目录'/',然后在父进程创建子进程(即调用syscall_exofork函数)时将子进程的当前目录设置为父进程的当前目录。
进程当前路径查询和修改
由于对于进程的操作应当由内核实现,因此此处我新增了两个系统调用以完成进程当前路径的查询和修改操作。
1234567int sys_get_dir(u_int envid, char path[MAX_ ...
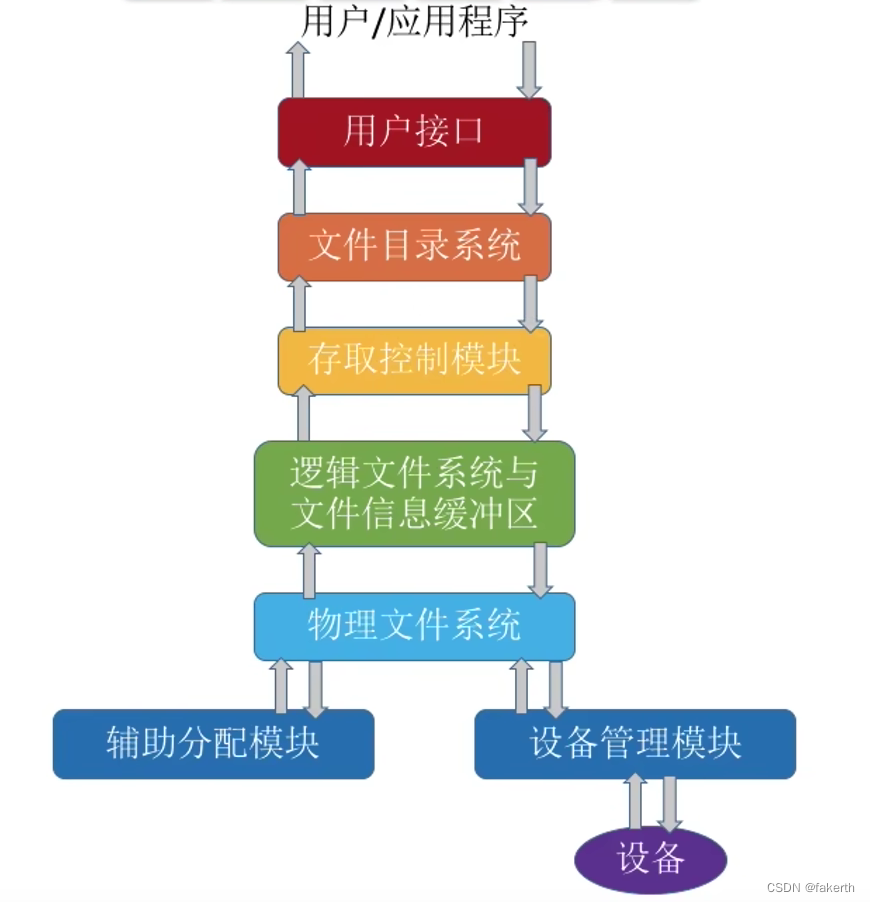
LAB5实验报告
思考题
Thinking1
如果使用kseg0进行设备读写,在写时将写入cache,而设备只能读内存中的数据,此时内存中的数据可能还未更新,设备将无法读到正确的数据。
对于串口设备由于其读写频率较高,发生上述错误的概率可嫩较高。
Thinking2
由定义可知,文件结构体大小为\(256B\),一个磁盘块大小为\(4KB\),易得一个磁盘块中有\(16\)个文件结构体。
目录中的各个文件结构体对应各个文件,因此目录中能得到的所有文件结构体数量即为一个目录下文件数量的最大值,一个磁盘块有\(16\)个文件结构体,目录中有\(1024\)个文件结构体,因此最多\(4K\)个文件。
单个文件中的指向的磁盘块存储文件内容,单个文件有\(1024\)个磁盘块,每个磁盘块\(4KB\),因此单个文件最大为\(4GB\)。
Thinking3
DISKMAX为文件系统进程地址空间中用于映射磁盘内容的域的大小,其定义如下:
1#define DISKMAX 0x40000000
可知其最大支持\(1GB\)的磁盘内容。
Thinking4
...
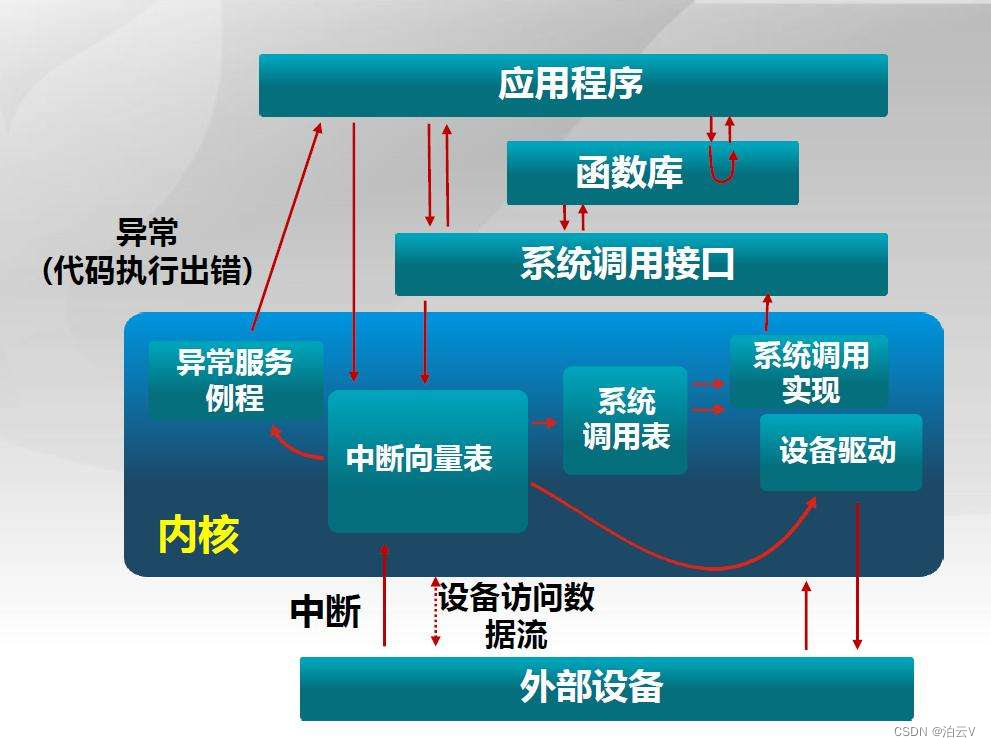
lab4实验报告
思考题
Thinking1
内核在保存现场时,通过SAVE_ALL宏实现保存现场,SAVE_ALL`宏具体实现如下:
1234567891011mfc0 k0, CP0_STATUSandi k0, STATUS_UMbeqz k0, 1fmove k0, spli sp, KSTACKTOP1:subu sp, sp, TF_SIZEsw k0, TF_REG29(sp)mfc0 k0, CP0_STATUSsw k0, TF_STATUS(sp)// TODO...
阅读上述代码可知,内核将栈指针指向KSTACKTOP然后将各个寄存器的值全部压入栈中,从而将现场的各个寄存器的值存入内核的栈空间中保护起来。
陷入内核后不可以直接从$a0~$a3中获得用户调用msyscall留下的信息,因为调用该函数后寄存器的值可以被修改,但用户空间原本的寄存器值已经被压入栈中保存起来,因此应当从栈中获取。
由于内核在保存现场时将现场的寄存器中全部压入栈中保存起来,同时将栈所指向的结构体指针作为参数传 ...

BUAA第三次迭代作业总结
架构设计
类图
本次作业主要任务是维护一个社交网络,由于三次迭代之间为增量设计,故此处仅展示第三次作业的UML类图。
第一次作业实现Network,Person,Tag,三个类,第二次作业实现OfficialAccount类,第三次作业实现Message类。
图模型
在社交网络的维护过程中,实际上是在对一个以Person为节点,边为社交关系的无向图进行维护,Person加入Network即为向次无向图中加入孤立点,为两个Person增加社交关系即为向此无向图加边,其余属性(如Message等信息)均可以视为在图中节点的附加属性进行维护。
大模型辅助规格化设计
本次迭代作业中,使用大模型的体验主要有以下几点:
目前大模型适用于根据实际要求生成JML规格。
对于一部分不需要使用其他数据的方法,可使用大模型根据该方法的JML规格直接实现代码。
大多数方法可能与其他方法直接相关,直接使用大模型较难实现具体代码,需要不断地向大模型输入其他类或其他方法的接口和返回值才能实现具体代码。
性能
根据社交网络维护这一目的,本次迭代作业涉及 ...
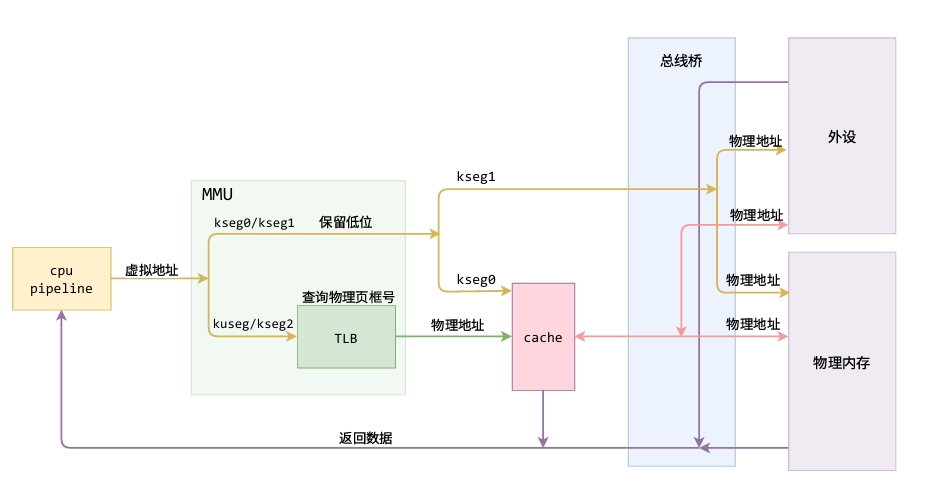
OS_lab2实验报告
思考题
Thinking 1
请根据上述说明,回答问题:在编写的 C
程序中,指针变量中存储的地址被视为虚拟地址,还是物理地址?MIPS
汇编程序中 lw和sw 指令使用的地址被视为虚拟地址,还是物理地址?
在C语言程序中指针变量储存的地址为虚拟地址,MIPS汇编程序中lw和sw指令使用的地址为虚拟地址
Thinking 2
请思考下述两个问题:
1. 从可重用性的角度,阐述用宏来实现链表的好处。
2.
查看实验环境中的/usr/include/sys/queue.h,了解其中单向链表与循环链表的实现,比较它们与本实验中使用的双向链表,分析三者在插入与删除操作上的性能差异。
将多条语句封装为一个宏,需要执行相应操作时直接调用宏即可,避免较长的重复代码,同时避免了函数调用过程中的压栈等操作,提高了性能也节省了空间。
在删除上,实验环境中的链表和本实验中的链表,除了访问节点的下一节点时本实验使用宏,其余部分表大致相同,性能上无太大差异,但是实验环境中的循环链表如果删除的节点不与头结点链接,则需要遍历循环链表找到待删除的节点,性能 ...

LAB1实验报告
思考题
Thinking 1.1
在阅读 附录中的编译链接详解
以及本章内容后,尝试分别使用实验环境中的原生 x86
工具链(gcc、ld、readelf、objdump 等)和 MIPS
交叉编译工具链(带有mips-linux-gnu- 前缀,如
mips-linux-gnu-gcc、mips-linux-gnu-ld),重复其中的编译和解析过程,观察相应的结果,并解释其中向objdump传入的参数的含义。
在~/myfile目录下编写print.c程序用以输出一段字符串,分别使用gcc -E print.c和mips-linux-gnu-gcc -E print.c后比较不同可发现由于使用的工具链不同其预处理后的.c文件中的除main函数以外均有所不同。
在相同目录下使用gcc -c print.c -o print_x86.out和mips-linux-gnu-gcc -c print.c -o print_mips.out只编译不连接后再使用objdump -DS <filename>.out > <filena ...
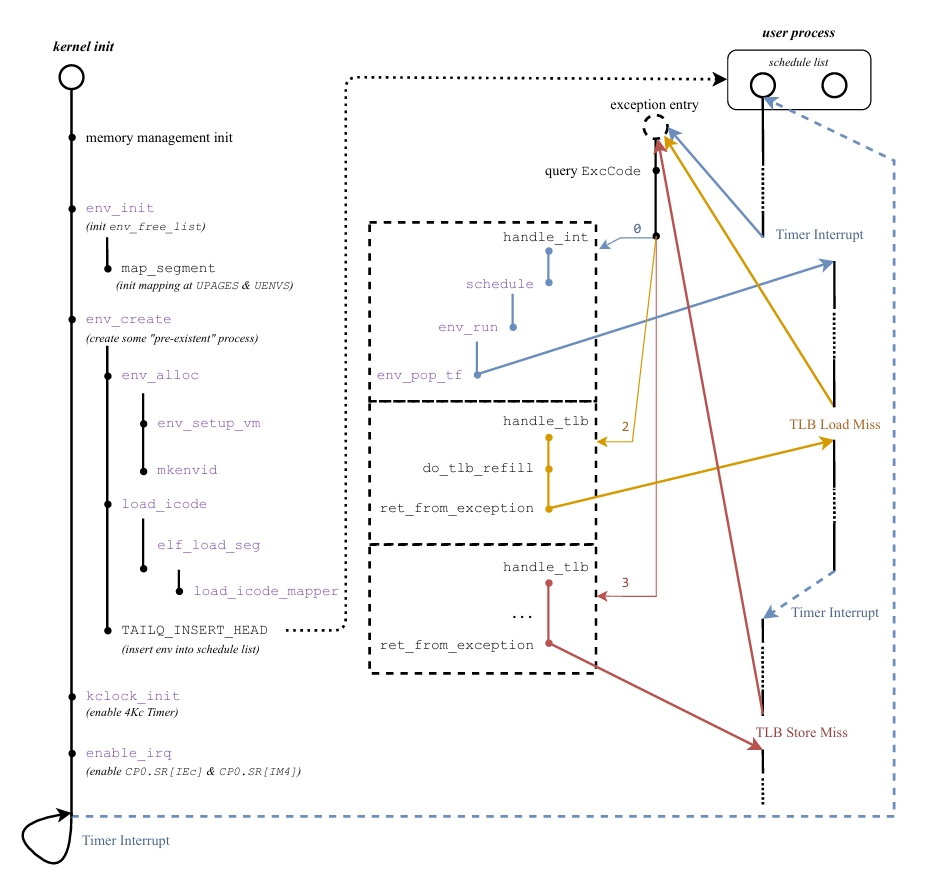
LAB3实验报告
思考题
Thinking 1
请结合MOS中的页目录自映射应用解释代码中e->env_pgdir[PDX(UVPT)] =
PADDR(e->env_pgdir) | PTE_V 的含义。
将页目录自身物理地址存储到页目录中虚拟地址为UVPT的页目录项中,并将其权限位设置为只读,完成页目录自映射。
1234567891011121314151617181920212223242526272829o KERNBASE -----> +----------------------------+----|-------0x8002 0000 |o | Exception Entry | \|/ \|/o ULIM -----> +----------------------------+------------0x8000 0000-------o | ...
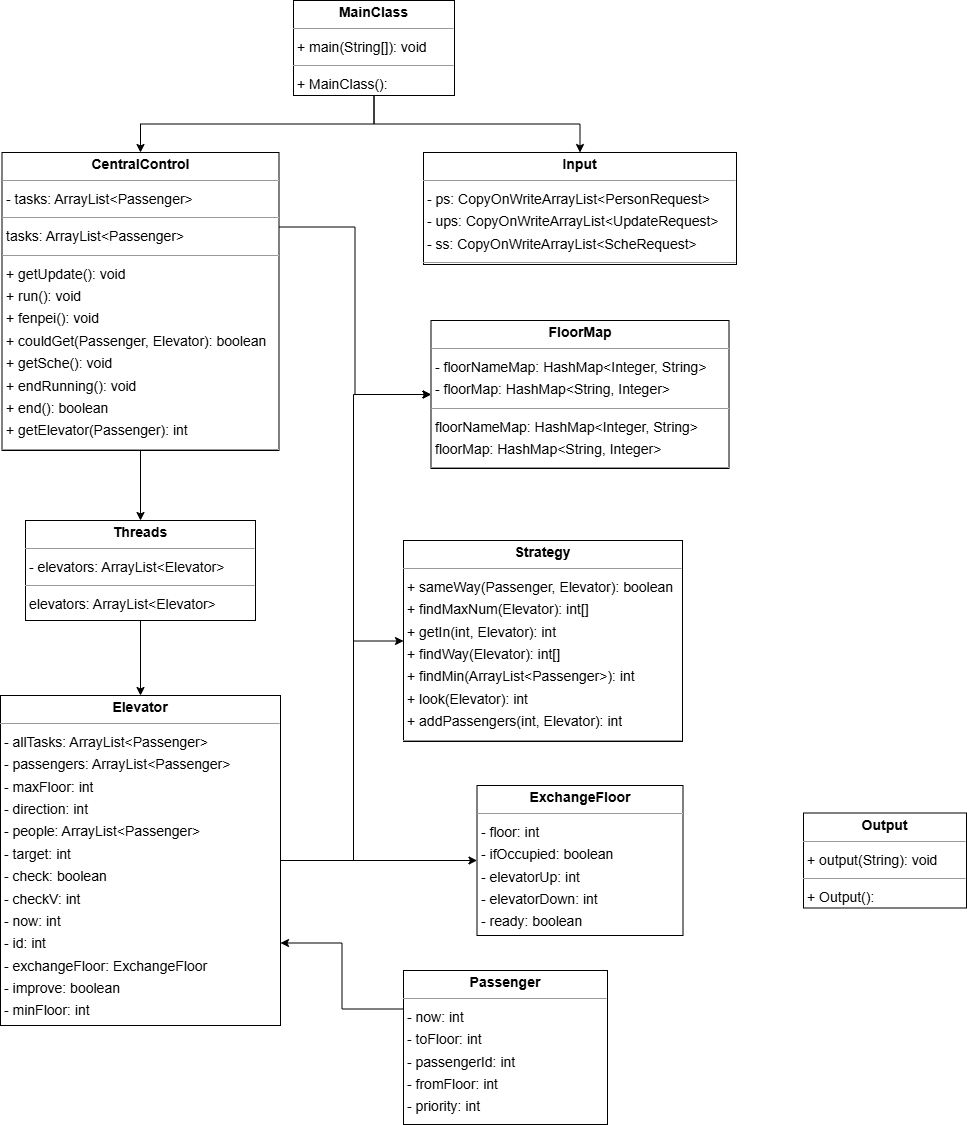
面向对象第二次迭代作业——电梯管理与多线程
作业任务
本次作业主要实现一个有6部电梯的电梯管理系统,每部电梯并行运行,因此考虑使用多线程编程
本次作业含有三次迭代,分别要求实现满足如下几点要求的程序:
乘客指定自己要乘坐的电梯并指明自己的起始楼层和目标楼层。
乘客不再自己指定电梯,由程序为其分配电梯,并加入了电梯的临时检修调度状态。
加入双轿厢电梯改造,指定两部电梯,指定两部电梯的公共楼层,并改造为双轿厢(共用一个电梯井,一个电梯在共享楼层以下运行,另一个在共享楼层以上运行)。
三次迭代架构
第一次迭代
UML类图如下:
UML协作图如下:
类的设计:
Input:继承Runnable,读取输入,传给CentralControl,输入结束后结束线程。
CentralControl:继承Runnable,终端控制线程,接收输入线程传入的电梯请求,根据其指定的电梯将各个请求分发给对应电梯,输入线程结束,所有电梯完成所有作业后,结束线程。
Threads:统一管理电梯线程的创建和结束。
Elevator:电梯线程,接受终端控制线程分发的任务 ...
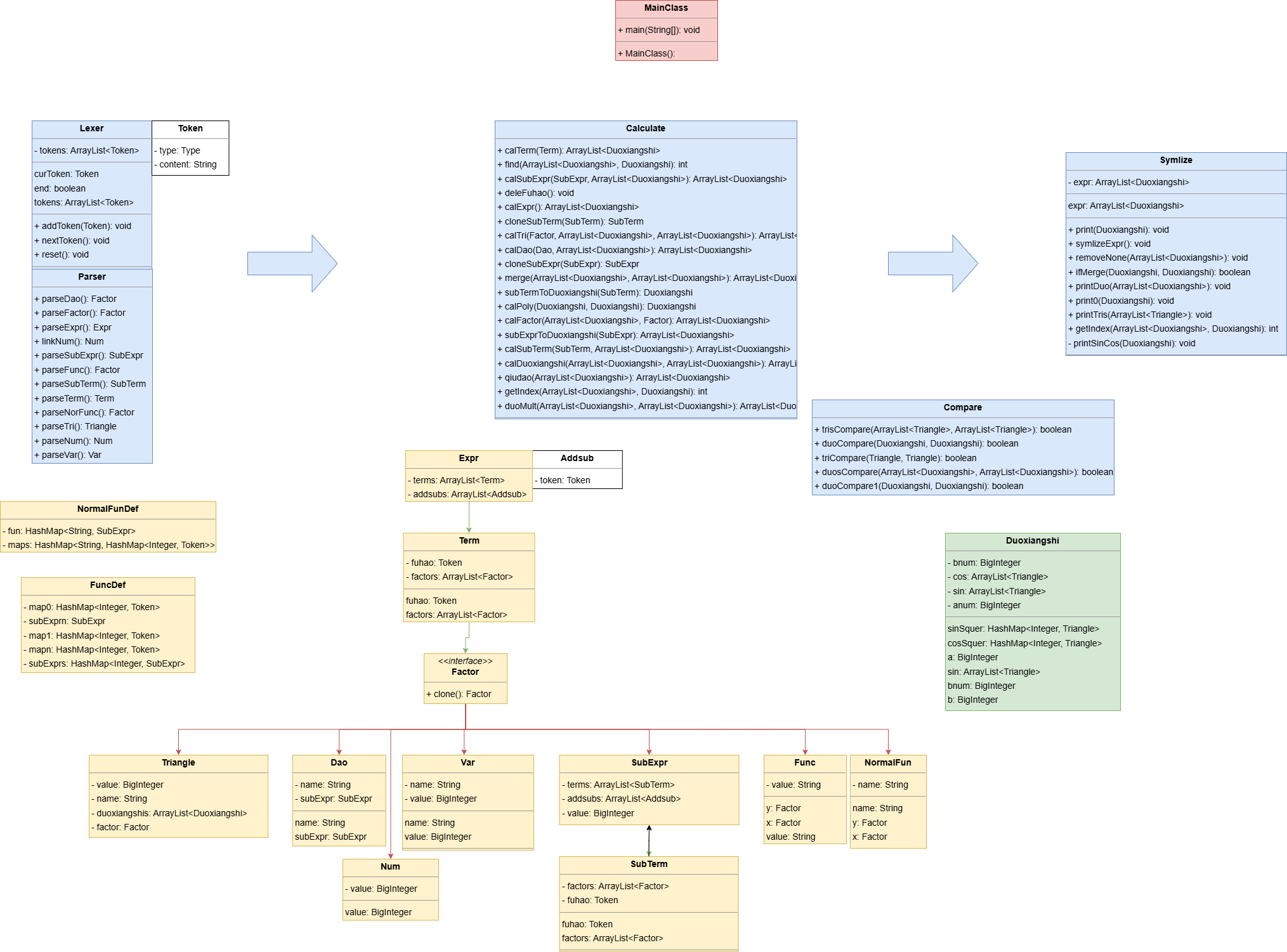
面向对象迭代开发总结-表达式化简
设计思路
在本次项目中,需要实现一个能够处理自定义普通函数,自定义递推函数,三角函数,导数表达式的表达式去括号程序。
各个设定的形式化表述如下(各项之间可存在空白符)
Exper = [+/-]Exper +/- Term
Term = [+/-]Term * Factor
Factor -> Var | Num | SubExpr | Dao(导数表达式) | Func(递推函数) | NormalFunc(普通函数)
Var = (x|y)^n
Num -> 整数
Dao = dx(Expr)
Func = f{k}(Factor,Factor) //可不含第二个Factor
NormalFunc = g(Factor,Factor)|h(Factor,Factor) //可不含第二个Factor
SubExpr = ([+/-]SubExpr +/- SubTerm)^n
整体思路如下:
词法分析将输入的字符串解析为Token列表。
递 ...
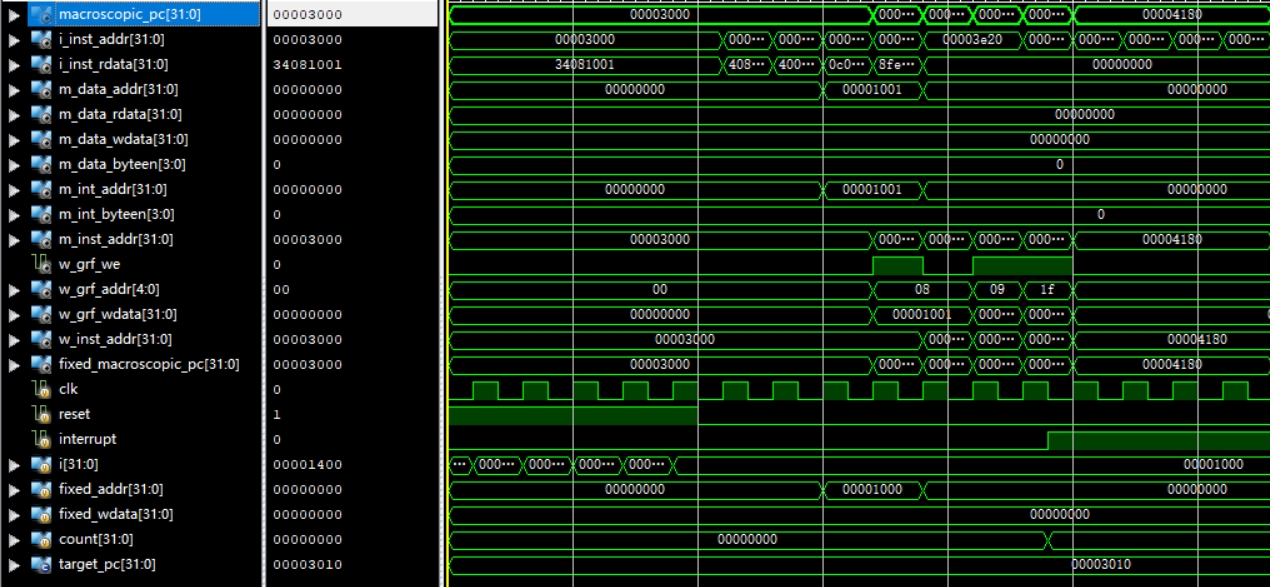
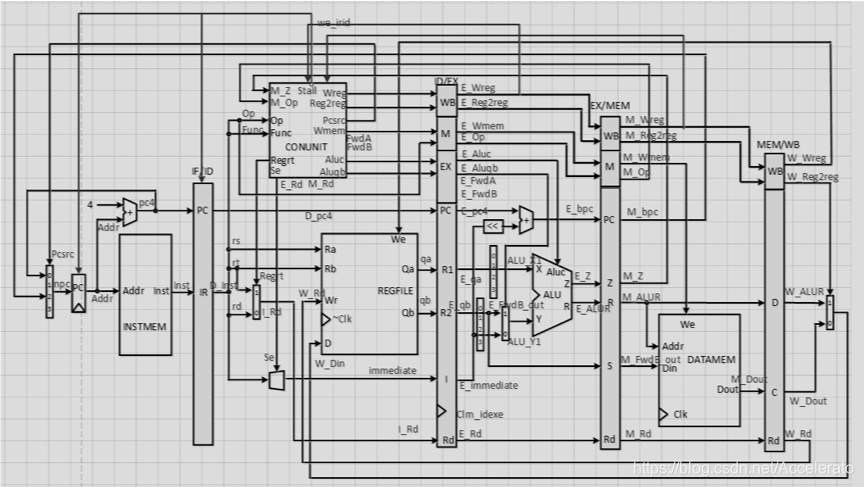
计算机组成
未读设计思路
基本结构
流水线寄存器,GRF等模块与P6相同,新增timer模块,bridge模块,cp0模块,形成如下图所示的结构。
其中timer模块采用课程组设计,bridge模块负责将cpu传出的数据与外界,timer模块相连,cp0模块负责响应异常和终端,并记录相关信息。
模块设计
bridge
主要用于传输数据,将数据发送至相应接口,部分代码示例如下:
123456789101112131415assign cpuReadData = (cpuDataAddr>=0&&cpuDataAddr<=32'h2fff)?memReadData: (cpuDataAddr>=32'h7f00&&cpuDataAddr<=32'h7f0b)?timer1ReadData: (cpuDataAddr>=32'h7f10&&cpuDataAddr<=32&# ...
